-
2. MSA 구현을 위한 핵심 프레임워크를 알아보자 1Spring Cloud 2021. 3. 25. 00:38
이번장과 다음장에서는 Micro Services Architecture(MSA)를 구축하기 위한 Spring Cloud 프레임워크의 핵심 라이브러리들의 개념을 알아보고자 합니다.
(원래는 한편에 모두 담으려 하였으나 내용이 길어져 두편으로 나눴습니다.)
핵심 라이브러리 들이 어떤 것들이 있으며 각각이 서로 어떻게 상호 작용을 하면서 MSA 환경이 구축되고 운영되어지는지에 대해 알게 된다면 막연했던 MSA 구축이 보다 명확해지리라 생각합니다.
Spring Cloud Framework
Spring Cloud는 Spring Boot 기반으로 제작되었으며, 클라우드 환경을 보다 편리하게 구축하기 위해 설계된 라이브러리 입니다.
이러한 Spring Cloud에서는 MSA 구축에 널리 쓰인 Netflix OSS 프레임워크의 핵심적인 라이브러리리를 포함하고 있습니다.
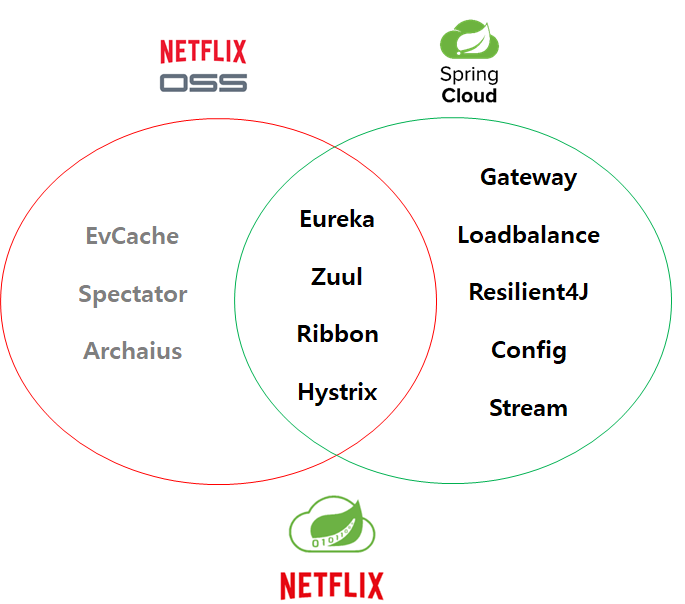
MSA 구축을 위한 주요 라이브러리 현 블로그에서는 Netflix OSS의 대표적인 핵심 라이브러리인 Eureka, Ribbon, Hystrix, Zuul과 Spring Cloud의 Config의 이론과 실습을 진행할 계획입니다.
Eureka, Ribbon,Hystrix,Zuul, Config의 5가지의 요소를 충분히 이해하고 구현해 보는 것이 개발 관점에서 MSA를 개념을 이해하는 시작이자 필수적인 요소이라고 생각합니다.
어려운 개발 없이도 단지 이러한 1) 라이브러리를 추가하고 2) 간단한 properties 설정하고 3) 특정 Annotation을 등록함으로써 손쉽게 Micro Services Architeture를 구현할 수 있습니다.
이번장(과 다음장)에서는 핵심 라이브러리들에 대해 개념을 잡고 이후 실제 개발을 진행함으로써 MSA의 핵심적인 전반의 프로젝트의 구축해 보도록 하겠습니다.
서비스 정보 관리는 어떻게?
앞선 장에서는 MSA는 최소한의 작게 쪼개진 서비스들이 서로 통신을 하며 연계한다고 하였습니다.
앞장에서 예를 든 쇼핑몰 그림을 다시 예로 들어 보겠습니다.

MSA 환경에서는 다양한 서비스들이 존재하며 각 서비스들은 고유한 IP와 PORT, 그리고 기본 정보를 가지고 있습니다. 그리고 서로 통신을 하기 위해서는 이 IP와 PORT와 같은 정보를 서로 알고 있어야 하겠지요.
하지만 MSA 클라우드 환경에서는 지속적으로 서비스들이 늘어나거나 변경될 수 있으며, 서비스의 부하에 따라 인스턴스가 늘어날 수도 다시 줄어들수도 있습니다.
만약 서비스가 수십~수백개가 된다면? 이정보들을 매번 직접 공유해야 한다면?
생각만 해도 끔찍하지 않은가요?
하지만 우리는 Spring Cloud의 라이브러리의 도움으로 이런 걱정을 덜어낼수 있습니다.
Micro Services Architecture(MSA)를 구축하기 위한 Spring Cloud 프레임워크의 핵심 라이브러리들의 개념을 알아보고자 합니다.
핵심 라이브러리 들이 어떤 것들이 있으며 각각이 서로 어떻게 상호 작용을 하면서 MSA 환경이 구축되고 운영되어지는지에 대해 알게 된다면 막연했던 MSA 구축이 보다 명확해지리라 생각합니다.
서비스들 간의 연계
앞선 장에서는 MSA는 최소한의 작게 쪼개진 서비스들이 서로 통신을 하며 연계한다고 하였습니다.
앞장에서 예를 든 쇼핑몰 그림을 다시 예로 들어 보겠습니다.
MSA 환경에서는 다양한 서비스들이 존재하며 각 서비스들은 고유한 IP와 PORT, 그리고 기본 정보를 가지고 있습니다. 그리고 서로 통신을 하기 위해서는 이 IP와 PORT와 같은 정보를 서로 알고 있어야 하겠지요.
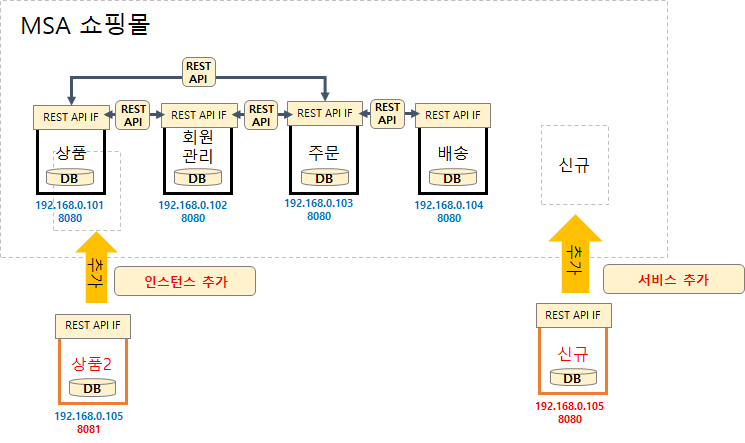
위 그림과 같이 상품에 대한 부하가 증가하여 상품 인스턴스가 추가 될수 있으며, 수시로 신규 서비스가 개발되어 추가되어 질수도 있습니다.
특히 MSA 클라우드 환경에서는 지속적으로 서비스들이 늘어나거나 정보가 변경될 수 있으며, 서비스의 부하에 따라 인스턴스가 늘어날 수도 다시 줄어들수도(Auto-scaling) 있습니다.
누군가가 자동으로 정보를 등록, 갱신하고 관리해 줄수는 없을까요?
다행히도 우리는 이런 걱정을 덜어낼수 있습니다. 바로 서비스 디스커버리 패턴이라는 좋은 방안이 있습니다.
서비스 디스커버리
앞서 말한 것과 같이 서비스의 인스턴스가 생성 혹은 소멸되거나 신규 서비스들이 지속적으로 증가하는 등 서비스의 정보가 지속적으로 바뀔 수 있습니다.
디스커버리 서버는 이러한 가변적인 모든 서비스의 정보들은 각 서비스의 고유ID(거의 변하지 않는)에 매핑하여 관리합니다.
그리고 각 서비스들은 지속적으로 1) 자신의 정보를 디스커버리 서버에 등록 하며 2) 다른 서비스들의 정보를 조회 합니다. 그럼 각 서비스들은 다른 서비스의 IP와 PORT를 몰라도 서비스의 고유ID만 가지고 연계가 가능해집니다.
이러한 서비스 디스커버리의 구현을 쉽게 도와주는 것이 Spring Cloud의 Eureka 입니다.
Eureka는 아래의 2가지로 구성 됩니다.
- Eureka Server (서버 라이브러리) : 서비스들의 정보를 관리, 제공
- Eureka Client (클라이언트 라이브러리) : 서버에 자신의 정보를 제공, 다른 서비스의 정보를 조회
말그대로 Eureka Server는 디스커버리 서버에 탑재되며, Eureka Client는 각각의 서비스들에 탑재됩니다.

위의 그림과 같이 각 서비스들이 기동될때 혹은 가동 중에도 지속적으로 자신의 정보를 디스커버리 서버에 등록(갱신)하며, 서버는 이 정보들을 캐싱하여 관리합니다.

이와 동시에 각 서비스들은 디스커버리 서버로 부터 다른 서비스들의 정보를 지속적으로 조회합니다.
(이 정보들 또한 기본적으로 서비스들이 캐싱하여 관리합니다.)
그리고 각서비스들은 서로의 고유ID만 가지고 연계가 가능합니다.
예를 들어 상품 서비스가 주문 서비스로 REST API 요청을 할때 IP와 PORT 대신 고유ID로 통신이 가능해집니다.
클라이언트측 부하 분산 (소프트웨어 로드밸런싱)
일반적으로 서비스 간에 HTTP 통신(동기식)을 할때 RestTemplate, WebClient(동기,비동기 지원)을 많이 사용하곤 합니다.
만약 상품서비스에서 주문서비스로 HTTP 통신을 한다고 하는 경우를 예를 들어 봅시다.
대다수의 서비스들은 단일 인스턴스로 구성되지 않고 고가용성을 위해 여러개의 인스턴스로 이중화되어 구성되어 집니다.
만약 주문서비스가 2개 이상의 인스턴스로 구성되어 있다면, 상품서비스는 어떤 인스턴스로 요청할지 어떻게 결정해야 할까요?
Spring Cloud(Netflix OSS)가 나오기 이전에는 보통 물리적인 L4를 주문서비스 앞단에 두어 로드밸런싱 하는 방법을 사용했을 겁니다. 클라우드 환경에서 물리적인 L4를 둔다는 것은 비용적인 측면이나 관리적인 측면 또한 유연성 측면에도 적합하지 않을 수 있습니다.

하지만 Spring Cloud 환경에서는 더이상 물리적인 L4를 사용하지 않아도 됩니다. 바로 Ribbon이라고 하는 라이브러리가 도와주니까요. (Ribbon과 비슷한 역할의 OpenFeig과 Spring Cloud Loadbalancer도 있습니다. 차이점은 다른 장에서 다루어 보겠습니다.)

앞서 각 서비스들은 Eureka를 이용하여 다른 서비스들의 정보를 캐싱하여 보관한다고 하였습니다. 여기에는 모든 인스턴스의 IP와 PORT를 포함하고 있습니다.
Ribbon 또한 Eureka Client와 마찬가지로 각 서비스들에 탑재되어 집니다.
만약 상품서비스가 주문서비스로 고유ID인 order로 요청하면 Ribbon이 Eureka로 부터 얻은 정보를 이용하여 정의된 알고리즘에 따라 자동으로 부하 분산을 해줍니다. (상품서비스는 주문서비스의 인스턴스를 알 필요가 없습니다. 오직 주문서비스의 고유ID만 알면 되지요.)
이를 클라이언트측 부하분산 혹은 소프트웨어적 로드밸런싱이라고 부르기도 합니다.
정리
이번 장에서는 Spring Cloud의 개요와 서비스 디스커버리, 클라이언트측 부하 분산을 알아보았습니다.
다음장에서는 API Gateway, 장애 전파방지와 복구, Config Server와 관련된 라이브러리를 알아봄으로써 Spring Cloud 전반적인 이해를 다지도록 하겠습니다.
'Spring Cloud' 카테고리의 다른 글
6. [MSA 구현 퀵스타트] HTTP 통신 Ribbon과 Feign 초간단 구현 (0) 2021.04.01 5. [MSA 구현 퀵스타트] 서비스 디스커버리 초간단 구현 (0) 2021.03.28 4. [MSA 구현 퀵스타트] 초간단한 MSA 개발하자 (2) 2021.03.26 3. MSA 구현을 위한 핵심 프레임워크를 알아보자 2 (0) 2021.03.25 1. Micro Services Architecture 란 (0) 2021.03.23